 abc
abc
abc
SUMMARY OF THIS PAGEAre two groups different from each other( given Interval or Ratio data)? What is Hypothesis testing? P values Ho and H1, Type 1 and Type 2 errors Paired 't' tests (Linked Page) More involvement with SPSS
The Unpaired 't'-test (student's) (Linked page)
|
We invariably have to take our data from samples and sample sets but in fact, what we are really interested in is the population from which those samples were taken. Inferential testing offers us an objective route to deciding if any measured differences or relationship that we have discovered from our samples are truly significant. Are they real differences or is it more likely that they came about purely by chance?
In other words; do they truthfully represent the population?
We now need to construct a theory or proposition to decide upon the issue...
An Hypothesis is a proposition (as yet unsubstantiated) which is tentatively accepted but must be tested to determine if it accords with the facts. The hypothesis can determine both the strength and direction of a relationship.
The 'direction of a relationship' needs explaining... If we say that the mean of 'A' is greater than the mean of 'B', we have only suggested one direction for any difference to take. If however, we said the mean of 'A' might 'just different from' that of 'B', we are suggesting that this 'possible difference' might be in one of two directions.
So:
|
testing
in one direction only =
|
a one-tailed test
|
e.g.
A is significantly larger than B
|
|
testing
in either direction =
|
a
two-tailed test
|
e.g.
A is significantly different from B
|
Hypothesis testing is concerned with making predictions. This may be predictions about differences between samples, predictions about outcomes,predictions about relationships or associations between variables.
With summary statistics, we simply extracted the basic information and moulded it into an easily digestible form.
We are now entering a higher branch of statistics known as inferential statistics.
(1) Our predictions have to be objective. They will not rely upon our personal opinions but on sound mathematical reasoning.
(2) Are the differences / similarities / relationships real or could they have arisen by chance?
Hypothesis testing requires us to make a prediction (in a formal way) and then to test statistically how likely it is that our statement is a true reflection of what has been observed or occurred.
The usual way to do this is to write the statement in such a way as to suggest that there is no difference, no similarity, no relationship. This is termed the Null Hypothesis and is the starting point for all inferential tests...
 Remember
the example of acid rain that we looked at in STEP 1?
Remember
the example of acid rain that we looked at in STEP 1?
Imagine now that we had collected 26 rainwater samples from two areas, each surrounding a different power station. One is oil-fired and the other is nuclear-powered.
"There is no significant difference in the dissolved SO2 levels taken from the two sites".
The task is not really to prove or disprove this statement but to calculate how likely it is to represent the true state of affairs. So we will either accept the statement as it is or have to accept some alternative statement. If we alter the statement, we must start over again.
So we will also require an Alternative Hypothesis and this will be the one we will accept if we cannot accept the Null Hypothesis.
"There is a significant difference in the dissolved SO2 levels taken from the two sites"
When considering the wording for your Null Hypothesis, make sure that the statement is clear, simple and unambiguous. Always clarify whether it is a one or two-tailed hypothesis because the subsequent choice of test depends upon it.
In mathematical
terminology we can write: 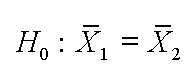 This indicates that the mean of sample one is the same as the mean of sample
2.
This indicates that the mean of sample one is the same as the mean of sample
2.
The correctly chosen statistical test will produce a 'test statistic', this will be compared to a critical value (usually derived from tables). In most cases, if the test statistic achieved fails to reach the level of the critical value, then the Null Hypothesis is accepted.
Conversely, if the critical value is exceeded, then the Alternative Hypothesis is accepted in place of the Null Hypothesis .
How does this come about?
When two samples are compared there will be a range (variation within each sample) and a variation between the two samples. Consider again the SO2 emissions from our two power stations...
Firstly, it is always a good idea to try to visualise or 'graphicise' your data. Our brains respond much better to pictures than they do to words. A quick visualisation like the one below can help us to decide what next to do with our data.
Here we can see the use of the 'Box and Whisker' plot. (using SPSS)
The 'box' gives a useful visualisation of the descriptive statistics being worked upon. The bold line delineates the mean and the red box indicates the position of the 25% (lower) and the 75% (upper) quartiles. Finally, the two 'whiskers' represent the full range of the data set.
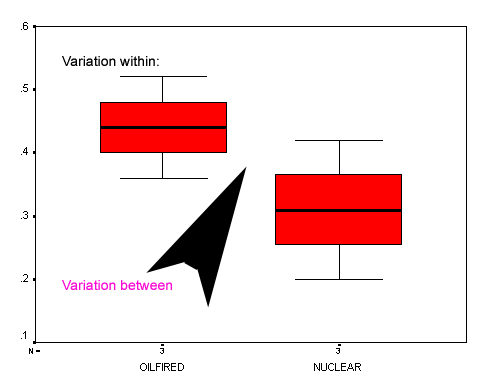
The oil-fired station is generally emitting higher level of SO2 but the nuclear station is displaying a wider range (and a larger variation: represented by the areas of the red boxes) albeit at lower levels. Also note that values between 0.36 and 0.43 actually overlap and could thus represent a sample taken from rainwater at either power station.
We might say that the variation 'between'(indicated by the black arrow) is explained by the simple fact that they are different types of power plant. The variation 'within' (from the lower whisker to the upper one) is more difficult to pin down; it may be due to varying rainfall, air temperatures, daily grid loadings, sampling problems or any other external factors.
In general, " The greater the ratio between explained and unexplained variation, then the more likely it is that the two means are significantly different"
Statistics can be used to help us describe chance occurrences. The tool we will use is called 'probability'
Probability is measured on a scale from 0 (absolute impossibility)(e.g. you will live for ever) to 1 (absolute certainty)(e.g. you will die one day). The more likely it is that something will happen; the closer the probability will be to 1. Also, if there are a number of possible outcomes; the probabilities of all of them will add up to 1.
 Imagine that a balloonist has fallen out of his balloon and that the balloon
is floating about in a totally uncontrolled and random fashion. The landscape
below comprises 70% agricultural land,15% urban development, 10% wasteland and
5% water.
Imagine that a balloonist has fallen out of his balloon and that the balloon
is floating about in a totally uncontrolled and random fashion. The landscape
below comprises 70% agricultural land,15% urban development, 10% wasteland and
5% water.
Then the probability of the balloon coming down on urban or wasteland is 0.15 + 0.1 = 0.25. Furthermore, if this happened 100 times!! we could say set up a null hypothesis that stated that the balloon was behaving in a random fashion. This would be tested. If indeed it did land on urban or wasteland exactly 25 times then our Null hypothesis would have been supported. The problem arises if it landed on that territory say 32 times or 16 times. Would the null hypothesis still hold true?
Should we have limits? For example, we may accept that 24 or 26 times still supports the null hypothesis but what about 30 or 20?
In a piece of scientific research, we want to know: " what is the probability (P) of the Null hypothesis representing the true state of affairs".
Once our chosen test has been applied to a data set and the test statistic obtained, we then need to know what was the probability of that result being obtained by chance. Was it one in ten, one in a hundred or one in a million likelihood level?. In some cases we might begin at the one in ten level which is expressed as: P(0.1). Using manual systems (tables) it is conventional to start by setting the 'cut off' point for the Null hypothesis to be accepted / rejected at the one in 20 level.
This is expressed as: P (0.05) = ####
If we wish to be even more stringent with our conclusions (as is always the case with drug trials for instance), then we may wish to use the one in one hundred chance.
This is expressed as: P (0.01) = ####
(SPSS may initially confuse here because it will always calculate the exact probability of the test statistic arising by chance but in practical terms, this is more useful as it means that tables are no longer needed.)
Having found the test statistic value: "if P < 0.05 reject Ho. If P >O.05, accept Ho".
Another way to view this is to say "At the 1% level, we will accept the results as significant (i.e. accept the Alternative) only if the result can be shown statistically to have happened by chance in less than one in one hundred times".
In mathematical terminology we can write:
given S (the test statistic calculated) if P<(0.05) then reject Ho
but if P >(0.05) then accept it.
 Try to relate this to a drugs evaluation trial for a new medicine.
Try to relate this to a drugs evaluation trial for a new medicine.
The null hypothesis will say that the drug will have no effect upon the recipient when compared to the effects of a placebo control. The effects (differences in response) are measured upon 100 patients.
|
Probability: Chosen Critical Level (value found in tables) |
Test statistic(S): Value arrived at (by calculation) |
What to do with the Null Hypothesis | What does this mean in simple language ? |
| P (0.05) | If S is less than 0.05 | Reject it and accept the alternative hypothesis |
It is likely that the differences noted did not occur by chance and are due to the influence of the drug |
| P (0.05) | If S is more than 0.05 | Accept it as it stands | Any differences recorded could have happened by chance in at least 5 of the 100 patients |
You can now see how we can 'set' the level at which we switch from acceptance of one hypothesis to the other. In field trials 5% uncertainty may be accepted, in drugs trials, only 1% or even 0.1% will be expected for safety reasons. Imagine a new drug that was likely to cause serious side effects in 5 out of every 100 patients....it could not be tolerated but in 1 in 1000 patients, it may be considered an acceptable risk.
We can now construct a 1-6 'critical pathway' to guide us through any inferential test procedure:
|
1
|
Decide on the exact wording of the Null Hypothesis and the Alternative hypothesis. Relate this to the original title of the experiment or investigation undertaken. |
|
2
|
Decide whether a one-tailed or a two-tailed test is appropriate and choose the test accordingly |
|
3
|
Calculate the Test Statistic (assume that Null is true) |
|
4
|
Compare the resulting Test statistic with the tabular value for P(0.05) and possibly P (0.01) |
|
5
|
Accept Null or the Alternative hypothesis as appropriate * |
|
6
|
State your conclusions and always relate them to the original hypothesis |
If you adhere to this procedure, you will have a much better chance of producing work that will stand up to scrutiny.
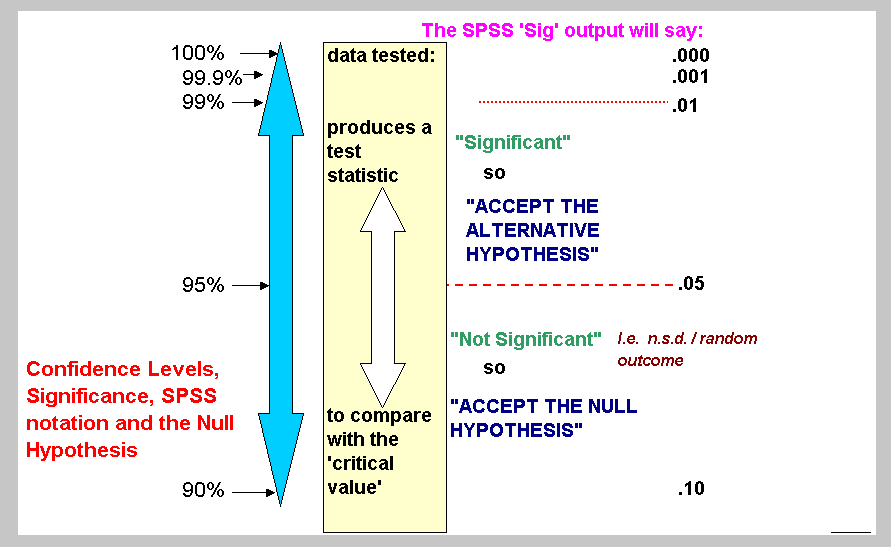
*SPSS gives you the direct level of significance (as a decimal) but it is not always easy to understand. The following chart should help.....
The concept of hypothesis testing (and switching) has many similarities with a court of Law..
 A
jury in a murder trial can return one of two verdicts...Guilty or Not Guilty.
We might say that the "Not Guilty" verdict equates to our Null Hypothesis
and the alternative would be "Guilty" but our presumption (our Null
Hypothesis) is always "innocent until proven guilty" because
we can only logically disprove something, not prove it. Similarly, we always
test the Null Hypothesis and NOT the Alternative Hypothesis.
A
jury in a murder trial can return one of two verdicts...Guilty or Not Guilty.
We might say that the "Not Guilty" verdict equates to our Null Hypothesis
and the alternative would be "Guilty" but our presumption (our Null
Hypothesis) is always "innocent until proven guilty" because
we can only logically disprove something, not prove it. Similarly, we always
test the Null Hypothesis and NOT the Alternative Hypothesis.
However the judge may direct the jury by saying that he would accept an eleven
to one verdict: i.e. at the 91.666% confidence [P(0.083)] level. In his summing
up, the judge might say "You have been found guilty of the crime beyond
reasonable doubt".
If scientists were asked to form a jury, what is the minimum number of jurors they would consider necessary to say "beyond reasonable doubt"?
No verdict can ever be said to be 100% certain and hence the phrase "beyond reasonable doubt". The same is the case with Hypothesis testing...nothing can be proven in the absolute sense but we can assign a particular level of confidence to our hypothesis statements and this brings us neatly back to our P-values.
Remember: we are equating "Not Guilty" with our Null Hypothesis....
|
CRIME |
CORRECT VERDICT HANDED DOWN |
ERROR VERDICT HANDED DOWN |
|
"No, the man really didn't do it"
|
NOT GUILTY (NULL) |
GUILTY (TYPE 1 ERROR)
|
|
"Yes, the man really did do it" |
GUILTY |
NOT GUILTY (TYPE 2 ERROR) |
Type 1 and 2 errors do not infer that you have necessarily made a mistake with your calculations (although you may have!) but it may be that the experimental design was flawed in some way and that led to flawed data being collected. The most likely factor here will be your choice of test. Both type 1 and 2 errors mean that the wrong hypothesis has been accepted.. either the Null when we should have accepted the Alternative or vice versa.
It is worth repeating how important it is to design your projects and experiments in such a way as to minimise the likelihood of false conclusions being drawn. It is irrelevant how deep the analysis becomes if you start off with flawed data.
We now have our 1-6 critical pathway so let's use it...
Go to Linked page for the Paired 't'-test